
Mathematics, 14.09.2019 04:30 hdjehd
4. classification models: logistic regression 4.1 create a new data set named auto2 that is identical to the auto{islr} data set (i. e., auto2=data. frame( then attach the auto2 data set – i. e., attach(auto2) 4.2 compute the median value of the miles per gallon values and store the results in an object named med. mpg. display this median. 4.3 create a new dummy variable in the data set named mpg01 to classify "high mileage" vehicles. this dummy variable will be = 1 if the mpg value is greater than the median and 0 otherwise. 4.4 set the seed to 1 (or any value you choose) to get replicable results. then draw a random sample of index numbers into a vector called train containing 80% of the row numbers in auto2. this vector will contain a random sample of 80% of the nrow(auto2) row numbers, which you will use to index the training sub-sample. note: your resulst will probably deviate slightly from mine because of the random sampling. 4.5 fit a logistic model on the training sub-sample, to predict the likelihood that a vehicle has high gas mileage (per the mpg01 variable) using cylinders, displacement, horsepower, weight, year and origin as predictors. store the results in an object named fit. logit. display the summary results. 4.6 briefly interpret the results, focusing on significant coefficients, deviance and aic. 4.7 as you know, the coefficients of this logit model represent the variable effects on the log-odds of having a high mileage car. but this is hard to interpret. to make this easier to interpret, create 3 vectors: log. odds containing the coefficients from fit. logit; odds containing the odds of these coefficients; and prob containing the probabilities that the coefficients represent. then use the cbind() function to diaplay all 3 vectors together. 4.8 now let’s do some cross-validation. use the predict() function with the attribute type="response" (which gives probabilities) to make predictions on the test data (tip: [-train,]) and save the results in an object named pred. probs. then create a vector named pred. hi. mpg containing a 1 if the probability of the vehicle being high mileage is greater than 50% and 0 otherwise (tip: use this function ifelse(pred. probs> 0.5, 1, 0)) 4.9 display a confusion matrix with these test predictions using the table() function (tip: use table(pred. hi. mpg, auto2$mpg01[-train])) 4.10 review the confusion matrix and then calculate (by hand, not with r code) the error rate, sensitivity and specificity (note: i will provide the r code to do this with the solution). 5. classification models: linear discriminant analysis (lda) 5.1 fit the same model from 4 above, but using the lda method, using again the training sub-sample. first load the {mass} library, then use the lda() function to fit the lda model and store the results in an object named lda. fit. 5.2 plot the lda. fit object. also display the lda. fit object (tip: just type lda. fit, without the summary function)

Answers: 2


Another question on Mathematics
Mathematics, 21.06.2019 15:00
Abag contains 3 red marbles 4 white marbles and 5 blue marbles if one marble is drawn from the bag what is the probability that the marble will be blue
Answers: 1
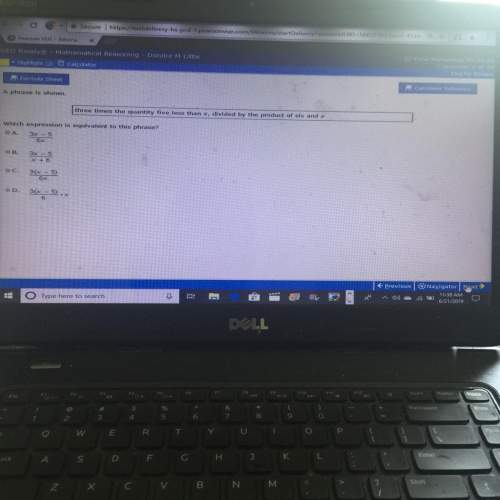
Mathematics, 21.06.2019 17:00
Which expression is equivalent to the expression shown?
Answers: 2
Mathematics, 21.06.2019 18:30
Can someone me out here and the tell me the greatest common factor
Answers: 1
Mathematics, 21.06.2019 19:00
Quick! a survey of 57 customers was taken at a bookstore regarding the types of books purchased. the survey found that 33 customers purchased mysteries, 25 purchased science fiction, 18 purchased romance novels, 12 purchased mysteries and science fiction, 9 purchased mysteries and romance novels, 6 purchased science fiction and romance novels, and 2 purchased all three types of books. a) how many of the customers surveyed purchased only mysteries? b) how many purchased mysteries and science fiction, but not romance novels? c) how many purchased mysteries or science fiction? d) how many purchased mysteries or science fiction, but not romance novels? e) how many purchased exactly two types of books?
Answers: 3
You know the right answer?
4. classification models: logistic regression 4.1 create a new data set named auto2 that is identic...
Questions





History, 13.04.2021 20:50
Mathematics, 13.04.2021 20:50

Social Studies, 13.04.2021 20:50
History, 13.04.2021 20:50

Health, 13.04.2021 20:50
History, 13.04.2021 20:50
Mathematics, 13.04.2021 20:50
Biology, 13.04.2021 20:50


